[TOC]
哈喽,大家好,我是 千羽。
之前新标签体系以及功能是一位T4的大佬做的,后面大佬离职了,所以我这边接的任务需要紧急把新标签体系用起来。(硬着头皮上)

哈喽,大家好,我是 千羽。
之前新标签体系以及功能是一位T4的大佬做的,后面大佬离职了,所以我这边接的任务需要紧急把新标签体系用起来。(硬着头皮上)
一、数据迁移背景
二、解决痛点问题
三、任务拆分
- 任务一:旧标签数据迁移到新标签
- 任务二:迁移旧标签对应的 SKU 到新标签 SPU 关系上
- 任务三:将新标签数据同步到 Elasticsearch
- 任务执行步骤
四、技术方案调研以及选择
- 方案一:Redis队列 + MySQL 实现
- 方案二:MySQL 实现
五、技术实现
- 新标签表对齐
- Redis队列 + MySQL 实现
六、关联关系迁移
七、结合哈希冲突的思想
八、错误处理与日志记录
九、成功的验证与测试
十、总结反思
一、数据迁移背景
做一件事情,先了解背景。
主要原因在于:原有的旧标签体系标签质量以及流程管理不足,并且在业务赋能也有限,未能发挥有效助力。
痛点一:
- 标签数据不规范: 标签数据可能存在缺失、重复或者不规范的情况,导致标签的准确性和一致性受到影响。
- 标签关联关系混乱: 标签之间的关联关系可能不够清晰,难以满足业务的需求,导致标签的应用受到限制。
- 标签更新不及时: 随着业务的发展,标签的含义和业务关联关系可能会发生变化,而标签的更新可能没有及时跟进,影响业务的敏捷性。
痛点二:
- 标签与业务融合不深: 标签体系未能有效融入业务流程中,比如存在数字0,1,2,感叹号,%¥……*@等等符号。无法为业务提供精准的支持,降低了业务的智能化水平。
- 标签对业务决策的贡献不足: 标签未能充分发挥在业务决策中的作用,未能为决策提供足够的智能支持。
- 标签对客户体验的影响有限: 标签在业务中未能对客户体验产生足够积极的影响,使得业务无法充分借助标签提升客户满意度。
痛点三:
- 信息不聚合: 查看标签关联资源或者查看资源下的标签,需要进行繁琐的SLUG查找,信息无法直观聚合。
- 展示不直观:标签库层级无法直接查看,标签自身层级展示不直观,标签在标签库中位置无法清晰展示,关联资源信息不直观。
- 筛选功能支持不足: 标签库中的搜索功能受限,库存中心、分发中心无法从标签纬度筛选资源。
痛点四:
- 查询链路太长: 在旧标签系统中,标签与SKU之间存在关联,而SKU又与SPU关联,导致在迁移过程中需要进行多次查询操作,形成了链路过长的问题。
- 复杂度增加: 长链路关系意味着每次迁移都需要经过多个关联表,增加了迁移的复杂度和耗时,降低了迁移效率。
二、解决痛点问题
所以针对以上四个痛点,建立起对应的解决方案,迁移标签数据迫在眉睫。要给业务方尽快新标签体系用起来。:
1. 提升标签质量
- 数据清洗与规范: 进行标签数据的全面清洗,确保数据的准确性和一致性。制定标签数据的规范管理规定,确保标签的命名和含义一致。
- 废弃旧标签体系机制: 建立新标签实时更新机制,废除旧标签体系,提高新标签的实效性。
2. 加强流程管理
- 标签创建流程优化: 设计清晰的标签创建流程,包括标签的提出、审批、发布等环节,确保每一步都得到妥善处理。
- 审批流程简化: 简化标签审批流程,减少冗余环节,提高审批效率,确保标签能够及时应用到业务中。
- 定期维护机制: 建立定期维护机制,确保标签信息的更新和维护工作得到及时执行,保障标签数据的时效性。
3. 强化业务赋能
- 深度融合业务流程: 将标签体系深度融入业务流程中,与业务系统进行紧密对接,使得标签成为业务决策的重要支持。
- 数据驱动业务决策: 通过标签体系提供的数据,深度驱动业务决策。建立数据驱动的决策机制,使得标签体系对业务决策发挥更大的贡献。
- 优化客户体验: 利用标签信息,优化客户体验。通过标签
4.关联关系优化:
- 关联关系迁移:重新评估和优化标签之间的关联关系,确保关联关系的清晰度和灵活性,使标签更好地满足业务需求。
- 标签库搜索功能: 优化标签库中的搜索功能,支持模糊搜索、根据slug等基础信息进行搜索,提高用户查找效率。
- 标签库层级优化: 重新设计标签库的层级结构,使得用户能够直接查看标签库的层级结构,便于了解标签的组织和分类。
- 标签展示直观化: 在标签展示页面中增加直观的展示方式,例如标签的树状结构图,清晰展示标签的层级关系。
三、任务拆分
先对任务进行拆分,我们可以将每个任务进一步拆分为更具体的步骤,以确保任务顺利完成。
要使新标签体系用起来,需要做三件事情。
任务一:旧标签数据迁移到新标签
数据迁移脚本编写
- 创建一个 PHP 脚本,使用 Eloquent 模型连接旧标签数据库,从旧标签表中读取数据,将数据插入新标签表。
迁移脚本执行
- 在终端中执行迁移脚本,确保旧标签数据成功迁移到新标签表。
任务二:迁移旧标签对应的 SKU 到新标签 SPU 关系上
数据迁移脚本编写
- 创建一个 PHP 脚本,使用 Eloquent 模型连接旧标签和 SKU 的关联表,将对应关系迁移到新标签和 SPU 的关联表上。
迁移脚本执行
- 在终端中执行迁移脚本,确保旧标签对应的 SKU 成功迁移到新标签和 SPU 关联表上。
任务三:将新标签数据同步到 Elasticsearch
Elasticsearch 数据同步脚本编写
- 创建一个 PHP 脚本,使用 Elasticsearch 客户端连接 Elasticsearch,将新标签数据同步到相应的 Elasticsearch 索引。
同步脚本执行
- 在终端中执行同步脚本,确保新标签数据成功同步到 Elasticsearch。
任务执行步骤
- 执行任务一脚本-数据迁移:先迁移旧标签数据到新标签表。
- 执行任务二脚本-关联关系迁移:迁移旧标签对应的 SKU 到新标签 SPU 关系上。
- 执行任务三脚本-同步elasticsearch:将新标签数据同步到 Elasticsearch。
确保在执行每个任务之前先备份相关数据,并在执行过程中监控日志,以便及时发现和解决问题。
这里先执行脚本一和脚本二。脚本三可以分开执行。
四、技术方案调研以及选择
这边针对业界技术方案进行调研,结合大厂的处理技术方案。结合三个角度出发:
- 保障迁移的稳定性: 确保在迁移过程中不发生数据丢失或不一致的情况。
- 提高迁移效率: 选择方案能够在大规模标签数据迁移时保持较高的性能。
- 降低维护成本: 选择方案不仅实施简单,而且在维护过程中的成本较低。
主要有采取Redis队列 + MySQL 实现和MySQL 实现
方案一:Redis队列 + MySQL 实现
“
把数据存入redis队列,然后取出数据进行消费。执行MySQL的Insert操作
优点:
- 容错性强: 使用灰度环境和 Redis 队列实现,具有较强的容错性,即使在迁移过程中断开连接,可轻松重新启动和恢复,采取几个进程同时消费队列。
- 并发处理: Redis 队列的特性允许并发处理,提高了迁移效率。
缺点:
- 内存占用: Redis 队列可能占用大量内存,尤其是在标签数据量很大的情况下,需要确保 Redis 服务器具有足够的内存,所以这里不能存放整张表的字段。
- 维护成本: 这种方案需要额外的维护来处理连接断开、重新连接等情况。
注意事项:
- 监控和日志: 添加足够的监控和日志,及时发现和解决任何问题。
- 定期清理: 定期清理 Redis 队列,以避免内存占用过多。
方案二:MySQL 实现
“
整理对齐新标签数据,进行MySQL插入操作
优点:
- 简单实施: 方案相对较简单,适用于较小的标签数据集。
- 容错: 每次处理少量记录,可以降低连接断开的风险。
缺点:
- 连接断开: 在大规模数据迁移时,可能面临连接断开的问题,特别是在灰度环境中。
注意事项:
- 批量处理: 调整每次处理的记录数,以平衡性能和连接稳定性。
- 事务处理: 使用事务保持数据一致性,即使在连接断开的情况下也能够回滚。
- 错误处理: 及时捕获和处理错误,确保迁移任务的稳定性。
结合技术团队评审方案:采取方案一:Redis队列 + MySQL 实现
根据系统的实际情况,可以根据以下几点进行综合决策:
- 数据量大小: 本次标签的数据量很大,采取方案一,并在处理时控制队列的大小。如果标签数据量较小,方案二可能更为简便;
- 系统稳定性要求: 灰度环境中进行跑脚本,进程容易断开。如果要求高容错性和灵活性,方案一是更好的选择;如果对连接断开的容忍度较高,方案二可能更为简单。
五、技术实现
在了解新旧标签的功能,以及关联关系之后和需求细节。以新标签为准,通过编写脚本进行操作。
新标签表对齐
- 确保新标签表的字段与新的标签体系的需求一致。如果新的标签体系有新增的字段或者旧字段发生变化,需要在新标签表中进行相应的调整。
数据清理:
- 清理新标签表中可能存在的无效或冗余数据,确保表中的数据符合新的标签体系的规范。
索引对齐:
- 如果新标签表与其他表有关联,确保关联索引的一致性,以避免数据查询时的性能问题。
数据格式对齐:
- 根据新的标签体系,检查新标签表中的数据格式是否符合要求,特别是涉及到日期、文本等数据类型的字段。
约束对齐:
- 确保新标签表的约束(如唯一约束、外键约束等)符合标签体系的设计,以维护数据的完整性。
Redis队列 + MySQL 实现
提前做好数据备份!!!!
再对标签存入redis,取id,name,slug三个字段。等全部存入redis队列之后,再开启三个进程消费者进行消费。
部分核心代码,这里通过php实现,采用Golang开启协程实现也是可以的。
六、关联关系迁移
这里有一个问题,标签,sku与spu是多对多的关系。
由于历史原因。
旧标签体系:标签-标签_sku-sku-spu
新标签体系:标签-标签_spu-spu
一个标签对应多个sku,多个sku对应一个sku
反过来,一个spu对应多个sku,一个sku对应多个标签。
如何保障不会出现重复迁移的数据呢?如何保障迁移的唯一性呢?
七、结合哈希冲突的思想
联想到之前阅读map集合的源码,发现可以采取解决哈希冲突的思想,通过”label_id - spu_id”组成key,
遍历新标签体系:label_id - spu_id
查询旧标签体系:判断新标签的key—-label_id - spu_id是否存在,存在就跳过。
- 生成唯一标识的哈希键:可以使用标签和 SPU 的组合作为哈希键。确保组合是唯一的,以避免迁移重复的数据。
- 在迁移前进行检查:在执行迁移脚本之前,可以先查询目标表,判断要迁移的数据是否已经存在。如果已存在,就跳过该条数据,以确保唯一性。
部分核心代码
```php
// 旧标签的key
$tmpKey = "{$oriLabelId}-{$spuId}";
$oriLabelIdMapSpuId[$tmpKey] = $tmpKey;
/**
* 获取新标签label_id与spu_id的映射关系
* @param array $spuIds
* @return array
*/
private function getNewLabelIdMapSpu(array $spuIds)
{
$maps = LabelSpuMapModel::query()->selectRaw('spu_id, label_id')->whereIn('spu_id', $spuIds)->get()->toArray();
$migratedLabelMaps = []; // 已迁移的关联关系
foreach ($maps as $val) {
$tmpKey = "{$val['label_id']}-{$val['spu_id']}";
$migratedLabelMaps[$tmpKey] = $tmpKey;
}
return $migratedLabelMaps;
}
foreach ($oriLabelIdMapSpu as $key) {
// 去重
if (isset($migratedLabelMaps[$key])) {
continue;
}
$notMigrateLabelMaps[$key] = $key;
}八、错误处理与日志记录
在迁移过程中,错误处理与日志记录非常重要!通过在脚本进行健壮的错误处理机制,及时记录了迁移过程中的错误和异常情况。这不仅帮助我们快速发现问题,也为后续的优化提供了有力的数据支持。先在本地进行测试,完了之后到线上进行处理。
九、成功的验证与测试
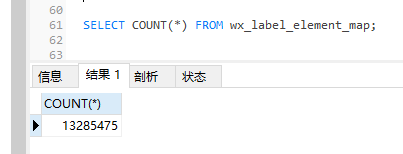
标签sku与标签spu表各占数据有1000多万:
| 标签_sku | 标签_spu |
|---|---|
 |
 |
最后脚本跑了三个小时多,终于跑完百万数据了,成功地迁移了百万级别的标签数据。在迁移结束后,我们进行了全面的测试和验证,确保新环境下的标签数据和业务逻辑与预期一致。
十、总结反思
做完了,不等于做好了,还需要考虑上下游的关系。
这里也是受到前同事大佬留下来的思想。
为什么会产生这批数据,能不能在源头上解决,如果不能解决or以后还会陆续出现,那么,就把他做成一个功能模块。避免以后再出现这样的问题。
在整个数据迁移过程中,不仅仅深刻认识到了数据迁移不仅仅是技术层面的挑战,更涉及到业务流程的整合与优化。在迁移过程中,但也面临到了一些问题。
例如,数据清洗和规范化过程中,需要确保每一步的准确性,以避免对新系统产生不必要的影响。此外,在迁移过程中,对业务的影响需要提前评估,确保迁移不会对业务正常运行产生负面影响。




